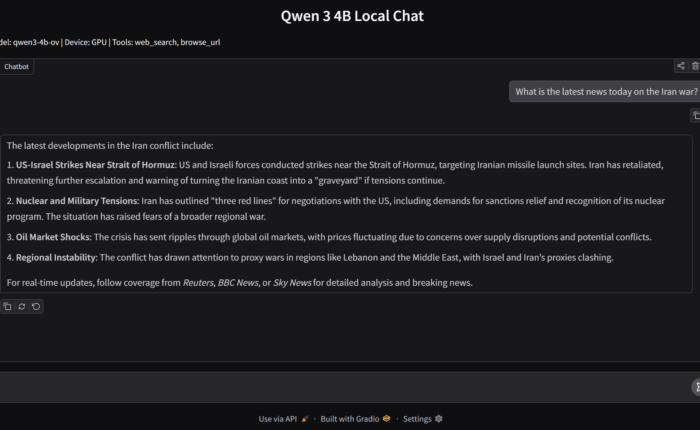
We have installed a local LLM in our laptop and used it as a chat bot, and tried coding with it as well. All’s well and good, right? Well, not really. Our local LLM still lacks a fundamental ability: tool calls.
You see, when we downloaded the LLM from HuggingFace and installed it, it comes with just its own set of training data. Meaning the information it has is limited only to the data it was trained on. This isn’t very helpful to us if we want to get up to date information, for example, today’s top entries in Hacker News. The LLM needs to access the internet to get that information, and by its own, it won’t be able to do that.