As software developers making web applications, most of the time we are engrossed in our own code. Designing features, thinking of the best ways to build it, and fixing bugs are what we do most of the time. We often treat our application as a black box, a standalone unit that accepts requests and spits out JSON or HTML. However, this is a shortsighted way of doing web development.
In this series we will explore the realm beyond the application that we are building. We will think of this as the journey of a web request starting from the user’s Web Browser (User), as it traverses through the Internet (Transit), and finally when it reaches the backend (Server).
Web Browser
As web developers, we are all familiar with the browser. This is our bread and butter tool. The main job of a web browser is to fetch content from the Internet and display it to the end user. It uses a standard markup language called HyperText Markup Language (HTML) in order to know how to display that content. Additional styling can then be done using Cascading Style Sheets (CSS) that control how that content is presented.
JavaScript (JS) is another core technology of the Web. It is a programming language that runs in the browser. This technology led to the creation of dynamic websites and web applications as opposed to just displaying static content, and today has a major role in web applications in general.
It does not matter to the browser where the HTML file comes from: a static file in your computer, a file somewhere in the Internet, or something that is generated by another computer. With the proliferation and popularity of JavaScript libraries and frameworks, it is highly likely that a website or web application you are using is essentially HTML generated using JavaScript code. As long as it is using the proper markup, the browser does not care about the source and will display it accordingly.
Browsers start to work once a user inputs a URL. This is not always done by typing into the address bar, however, as there are also other actions that prompt the browser to fetch content:
- When a user clicks a link within the page
- After submitting a form or clicking a button
- Redirects done by the server or the page itself
- Accessing the browser’s bookmarks or saved links
URL
A Uniform Resource Locator (URL) is a standard way of representing the location of a resource with a computer network. URLs can be used in a local network or a global network, such as the Internet.
URLs are a subset of a Uniform Resource Identifier (URI). Although URL and URI are sometimes used interchangeably, they are slightly different in a sense that some components of a URI (such as the userinfo) are not used in a URL.
URL Format
The standard format of a URL is shown below:
scheme://host:port/path?query#fragment
Let’s take a look at each of the components.
- scheme – this is the protocol used for the request, such as https or file
- host – where the request goes to. It can either be a domain/subdomain or an IP address
- port – specific port used in the host, which defaults to port 80 for HTTP
- path – the location of the resource in the host, such as the specific HTML file to display
- query – additional parameters that can be added to the request
- fragment – identifies a more specific part of the path to be displayed. In an HTML page, this will display the part of the page/element that has an HTML ID equal to the fragment
On a standard web request, such as a Google search query:
https://www.google.com/search?q=internet
- scheme – this request uses HTTPS, which means that the data sent to the server is encrypted in transit
- host – this request goes to the Google servers to process the search query
- port – as the port is not specified, this means that it is using the default port, which is 80
- path – for this example, “search”, means that it is processed by a routing mechanism that handles the “search” path
- query – there is a query parameter called “q” that is set to “internet”. This means that the “search” path must handle the “internet” search keyword for this request
- fragment – the example does not use any fragment in the request
Routing
In the early days of the Internet, the path component usually refers to a specific HTML file stored in the server, like search.html. As websites become more dynamic and complex, creating a separate HTML file for each of the possible paths in your website is no longer feasible.
Modern web applications now use a concept called routing that allows handling of requests depending on the path component. For a URL like https://google.com/search, this does not necessarily mean that there is a search.html file in the Google servers, but instead there is code in the server that generates the HTML response based on the values of path (search) and query.
For web applications using JavaScript client code, such as Single Page Applications (SPA), it is also possible that the routing mechanism is not even handled by the server. This means that even if the path component changes in the URL (e.g. when you click a link in the page), it may not depend on the server to generate the HTML response. Instead, the contents you see in the page are handled by the JavaScript code that is running in your browser.
DNS
When a user inputs a URL in the browser, the browser then contacts the server to fetch the HTML response. However, the server cannot be contacted directly using its domain name (e.g. google.com). Servers are located and identified in the Internet by its IP address. So there must be a way to determine the server’s IP address using a domain name.
Enter the Domain Name System (DNS). The primary purpose of DNS is to translate a domain name into an IP address so the browser can connect to it. Sounds simple enough, right? We just need a database somewhere that maps a specific domain name to an IP address. It turns out, this is not as simple as it sounds, given the massive number of domain names and the global scope of the Internet.
How DNS works
When the browser uses DNS, it involves four systems in order to translate a domain name:
- DNS Recursor
- Root Nameserver
- TLD Nameserver
- Authoritative Nameserver
DNS Recursor
This is the system that does most of the heavy lifting to translate a domain name into an IP address. It is responsible for communicating with other systems in order to provide the browser with the result. The recursor contacts different nameservers recursively until it arrives with the desired IP address of the server. This process is illustrated in a diagram shown later.
Root Nameserver
This handles the request for getting the address of the Top Level Domain (TLD) Nameserver. There are only 13 root server addresses, indicated by the letters A to M. Some examples are:
- https://a.root-servers.org/
- https://b.root-servers.org/
- https://c.root-servers.org/
- https://h.root-servers.org/
- https://m.root-servers.org/
Traditionally, these servers are mostly located in the United States, with other servers in Stockholm, Amsterdam, and Tokyo. At present, root servers use a system called anycast, which allows other servers to be located globally using the same IP address, thus improving global availability.
TLD Nameserver
The Top Level Domain (TLD) is the last part of a domain name. For example, the TLD for google.com is com. The most common TLDs are com, org, and net. The TLD nameserver is responsible for returning the address of the Authoritative Nameserver of a specific domain. So, for domains such as wikipedia.org and google.com, it means they are pointing to different TLD Nameservers, which are the org and com nameservers respectively:
- com – https://www.iana.org/domains/root/db/com.html
- org – https://www.iana.org/domains/root/db/org.html
Authoritative Nameserver
The actual IP address of the domain name is provided by the Authoritative Nameserver. If you have purchased a domain before, you may have set the nameserver settings as well. For example, you set it to Cloudflare or AWS Route 53 if these are the DNS providers you intend to use. These services provide their own nameserver URLs which basically sets them as the Authoritative Nameserver. This allows changing the DNS settings such as the A, CNAME, or MX records within that service.
DNS Process
The following illustration shows the process of resolving a domain name into an IP address using the Domain Name System.
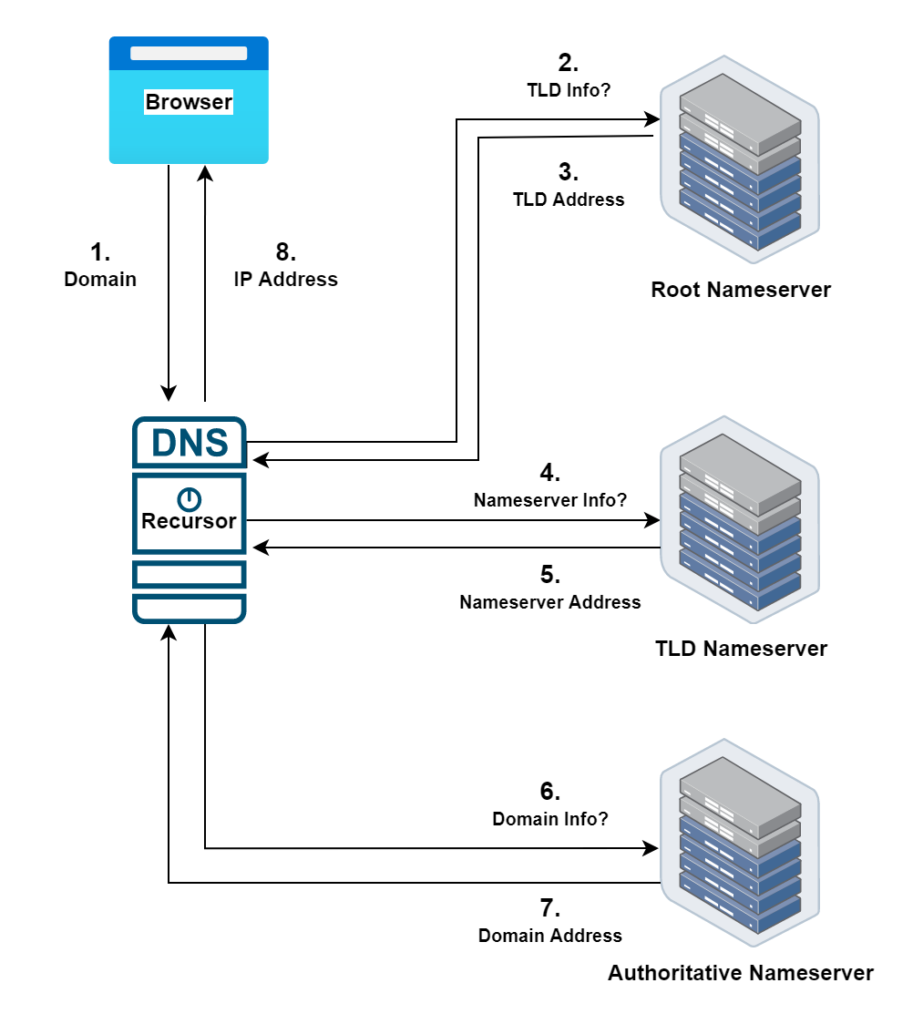
- The browser wants to determine the IP address of a domain, e.g. google.com. If the DNS record is not cached locally, it then asks the DNS Recursor.
- The DNS Recursor starts the process by fetching the address of the TLD Nameserver for the com TLD from the Root Nameserver.
- The Root Nameserver responds with the address of the com TLD Nameserver.
- The DNS Recursor then contacts the TLD Nameserver to get the address of the Authoritative Nameserver for the google.com domain.
- The TLD Nameserver responds with the information of the Authoritative Nameserver.
- The DNS Recursor then contacts the Authoritative Nameserver to get the IP address of the google.com domain.
- The Authoritative Nameserver provides the information to the DNS Recursor.
- The DNS Recursor gets back to the browser with the IP Address of the google.com domain.
Caching
As we can see, resolving a domain name into its IP address takes a lot of steps and involves multiple systems. To improve performance, there is a concept called DNS caching that allows your local machine to resolve domain names within your computer. These can be implemented as:
- Browser DNS Caching – the IP address of domains are stored within the browser for faster translation
- Operating System DNS Caching (Stub Resolver) – the OS stores the IP address of the domain in addition to the browser-level cache
While this improves performance and efficiency, there is an inherent risk associated with caching. If a malicious agent (such as a fraudster) manages to trick a DNS Recursor into thinking that it is a valid Nameserver, then the fraudster can inject incorrect DNS data into the cache. This is called DNS Cache Poisoning or DNS Spoofing.
When this happens, a user accessing a “poisoned” DNS cache can be led into a completely separate server impersonating as the legitimate server. For example, users can be tricked into entering their bank account details into a fake website that looks like the real bank website. This is difficult to catch as the browser will display the correct URL.
This is being handled currently by standardizing and implementing security measures when performing requests within the DNS system. In the meantime, if you suspect malicious activity, you can manually flush (or clear) the DNS cache on your browser or operating system.
At this point, the web request is now able to leave the user’s browser towards the server. In the next article, we will explore how the request passes through the Internet, and how browsers and servers communicate securely.
One thought on “Web Development Basics: User”